




Por Dra. Angélica Urrutia Sepúlveda, académica Universidad Finis Terrae y Académica MBA USACH
El éxito o correcto desempeño de las empresas en la actualidad depende de la explotación de los recursos intangibles (datos), es por ello que la gestión de la información o Business Analisys requiere de procesos de calidad para el apoyo a la toma de decisiones. En este contexto, la problemática a discutir se enfoca en el area comercial de una Compañía de Seguros, centrada en el sistema que utilizan las características del cliente y datos de la cartera asociado al proceso de fidelización de clientes.
La automatización de este tipo de problema se logra al utilizar técnicas de minería de datos y la metodología CRISP-DM, donde los resultados experimentales muestran las ventajas de utilizar algoritmos de árbol de decisión, naieve bayes, red neuronal, entre otros. Es importante utilizar métricas para la evaluación y selección del algoritmo que cumpla los requisitos para resolver este tipo problema, y en su implementación se aplican técnicas de Mineria de Datos y una arquitectura de Business Intelligence (BI) de SQL Server, como solución a sistemas de apoyo a la toma de decisiones en un Business Analisys.
El planteamiento del problema a discutir es interiorizando en la compañía de Seguros y al personal del área comercial, tomando en cuenta que representa el 22% de la producción anual de pólizas individuales, y que principalmente cumple las siguientes funciones: a) Captación de nuevos y fidelización de los clientes, b) Organizar los equipos de fuerzas de ventas a nivel nacional, regional, la Figura a), muestra una gráfica de Ventas Cruzadas (Cross-Selling) que propone la estrategia o patrones a seguir para la realización del proceso: Analizar y segmentar a los clientes, Elegir el mejor producto recomendado, Análisis de la canasta de mercado. Estos patrones deben ser considerados en la metodología de minería de datos CRISP-DM para la implementación la propuesta realizada.
Adentrando en las técnicas de minería de datos que mejor se adecuan para dar solución a la problemática planteada, hay que considerar que un algoritmo de minería de datos (o aprendizaje automático) es un conjunto de heurísticas y cálculos que permiten crear un modelo a partir de datos. Para crear un modelo, el algoritmo analiza primero los datos proporcionados, en busca de tipos específicos de patrones o tendencias. El algoritmo usa los resultados de este análisis en un gran número de iteraciones para determinar los parámetros óptimos para cada modelo de minería de datos. Finalmente, la Matriz de confusión y Métricas de evaluación (Tabla b)) entregan el mejor algoritmo para cada caso.
La Metodología para minería de datos CRISP-DM, es actualmente la guía de referencia más utilizada en el desarrollo de proyectos de Minería de Datos, la cual está estructurada en 6 etapas que se discuten a continuación:
Compresión del negocio: El proceso de ventas cruzadas es realiza de forma manual, ahora bien, los datos utilizados corresponden a la producción o pólizas emitidas a clientes naturales en un período de los últimos 5 años. Estos datos son proporcionados en formato Excel focalizados en dos tablas: Pólizas y Clientes, de los cuales contienen los datos de la Tabla b), para su automatización.
Comprensión de los datos: La selección de los algoritmos y los datos que cada uno requiere son preparados según la definición de la Tabla b). Arboles de decisión: sClient, sSex, sOcup, sStatus, dBirthdat, sOffice, nBranch. Naive bayes: sClient, sSex, sOcup, sStatus, dBirthdat, sOffice, nBranch. Redes neuronales: sClient, sSex, sOcup, sStatus, dBirthdat, sOffice, nBranch.
Preparación de los datos: La etapa de limpieza y preparación de los datos, y se utiliza SQL Server Data Integration para:
a) Eliminación de datos duplicados de la tabla pólizas y datos nulos de las columnas sSex, sStatus de la tabla de clientes, b) Cálculo de la edad a partir de la fecha de nacimiento, c) Se crea un identificador único para agrupar las pólizas que adquirió un cliente en un año determinado, d) Se actualiza el datos de nBuyerAutomotor, nBuyerMundisalud, nBuyerAMF, ya que este dato indica si un cliente ha comprado una póliza de automotor, mundisalud o AMF. Finalmente, los datos están preparados para aplicar los algoritmos de minería de datos elegidos: Árboles de decisión, Redes neuronales, Naive bayes. (véase Figura b))
Modelado: En la aplicación de cada algoritmo se debe implementar en forma individual, aquí se aplica primeramente el algoritmo de Reglas de asociación debido a que este da como resultado itemset (conjunto de productos) de pólizas que un cliente podría adquirir o pólizas que también adquirieron otros clientes. En segundo lugar, los algoritmos de Arboles de decisión, Naive bayes y Redes neuronales para obtener una predicción de sí un cliente pudiese adquirir una póliza del ramo automotor, este resultado es de gran utilidad para un ejecutivo comercial, que obtendrán un índice de probabilidad de compra de una póliza del ramo automotor para cada cliente.
Para la realización del modelado la utiliza Microsoft SQL Server Analysis Services, permite modelar los algoritmos mencionados anteriormente y dar apoyo al proceso de ventas cruzadas.
Evaluación: La implementación permite la evaluación de los modelos Arboles de decisión, Naive Bayes y Redes neuronales, utilizando la matriz de confusión y métricas de evaluación, dando como resultado la Tabla a):
Tabla a). Matriz de confusión y Métricas de evaluación.
| Accuracy | Precision | Recall | F1 Score | |
| Arboles de decisión | 0,7168 | 0,6623 | 0,5980 | 0,6285 |
| Naive Bayes | 0,6389 | 0,5712 | 0,3957 | 0,4675 |
| Redes neuronales | 0,6370 | 0,5807 | 0,3383 | 0,4275 |
Aquí al observar los valores de las métricas, se puede apreciar que, de los 3 modelo comparados, el que presenta mejores indicadores es el algoritmo de Arboles de decisión.
Resultados y discusión: Los resultados muestran que la aplicación de técnicas de minería de datos en el proceso de fidelización de clientes a través de las ventas cruzadas, resulta de bastante utilidad, los datos encontrados a partir del análisis de la información proporcionada y su aplicación como datos entrada en el algoritmo de reglas de asociación, muestran resultados de datos que serán utilizados por los ejecutivos comerciales para la colocación de más pólizas entre los clientes existentes, como apoyo a la toma de decisiones.
Para una segunda propuesta de la utilización de las técnicas minería de datos en el proceso de fidelización de clientes, la comparación de la implementación de los algoritmos de Arboles de Decisión, Naive Bayes y Redes Neuronales, se obtiene un conjunto de características de los clientes y que deben ser tomados en cuenta para que los ejecutivos comerciales aumenten su efectividad en el proceso de venta de una nueva póliza.
Finalmente, Es importante elegir una metodología para la implementación de minería de datos, ya que marcan las etapas que se deben realizar para su correcta aplicación y por ende obtener mejores resultados.
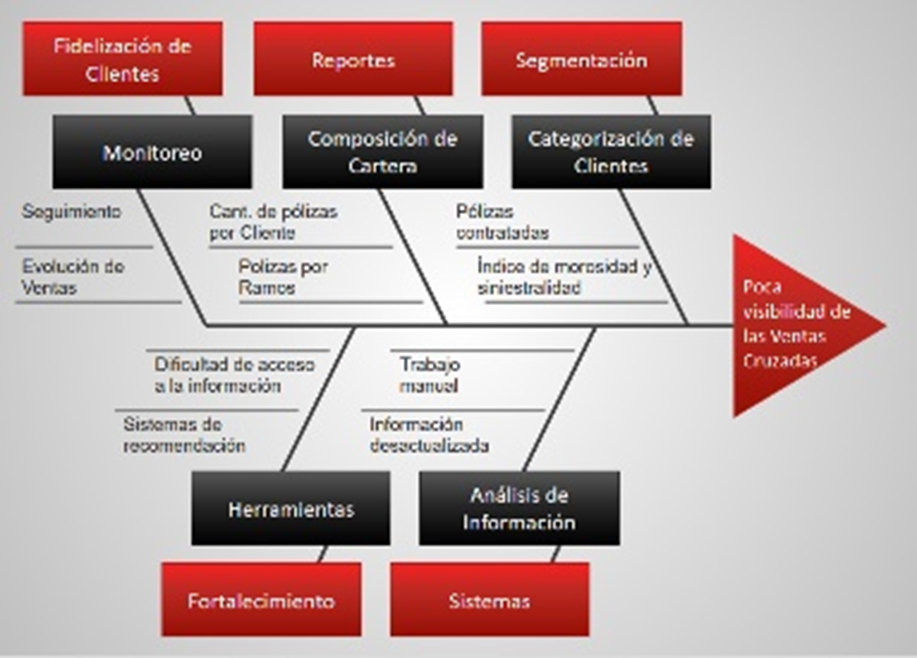
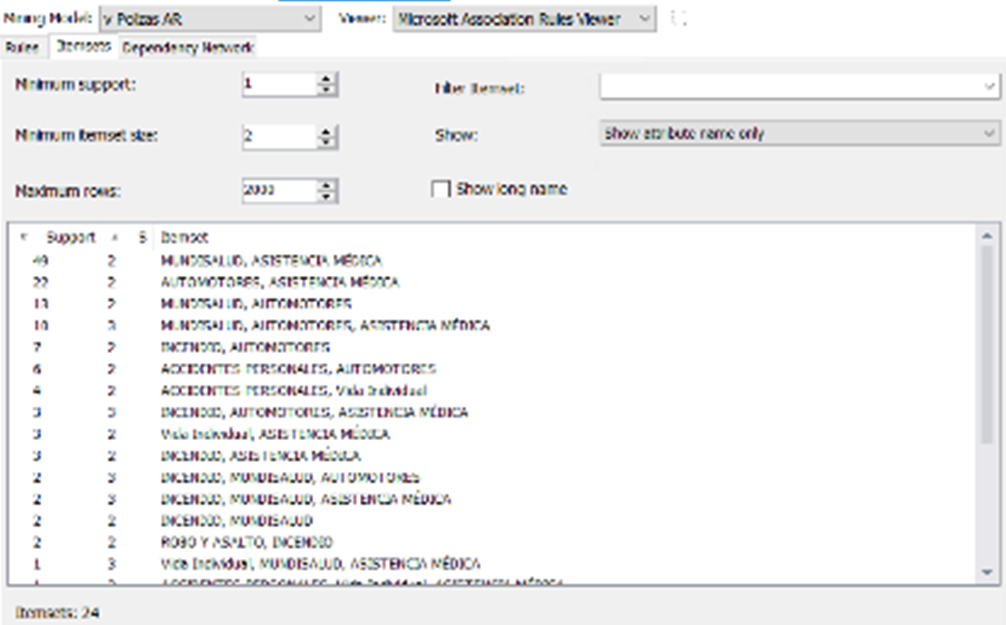
Tabla b). Descripción de Datos seleccionados para Ventas Cruzadas
| Tabla | Campo | Descripción |
| Pólizas | sClient | Cliente contratante |
| nYear | Año que fue adquirida la póliza | |
| nBranch | Identificador del ramo de la póliza | |
| sBranch | Descripción del ramo de la póliza | |
| nId | Identificador único del registro | |
| sOffice | Ciudad | |
| nPolicy | Número de póliza | |
| Clientes | sClient | Cliente contratante |
| sCliename | Nombre del cliente | |
| sSex | Género del cliente | |
| sOcup | Ocupación | |
| sStatus | Estado Civil | |
| sClien_typ | Tipo de cliente | |
| dBirthdat | Fecha de nacimiento | |
| dCompdate | Fecha del registro |
Este artículo corresponde a los resultados de una tesis de Magíster de la Universidad Católica de Boliviana «San Pablo», Santa Cruz de la Sierra, Bolivia. Maestría en Inteligencia de Negocios. Maestrante: Leonardo González Terrazas.
Dra. Angélica Urrutia Sepúlveda, Directora de Escuela de Ingeniería Civil. Universidad Finis Terrae y Académica MBA USACH.


